
Les données externes peuvent être utilisées pour améliorer les performances globales de l’entreprise. Cependant, tout d’abord, approfondissez la manière dont les données externes sont extraites et mises en œuvre dans les pratiques de gestion.
L’utilité des données externes augmente chaque année. À mesure que l’acquisition devient plus omniprésente et accessible aux petites entreprises, les applications de données externes prolifèrent. Cependant, la bonne gestion de ces données continue d’être un problème. Une enquête menée au cours des dernières années a montré que même les entreprises légendaires peuvent avoir du mal à gérer les données.
Avant de continuer, je vous recommande vivement de lire mon article précédent sur ce sujet. Sauter dans les données externes, leur acquisition et leur gestion serait plus facile si les bases adéquates étaient déjà posées.
Comprendre les données externes
Cela peut sembler simpliste au premier abord. Cependant, les données externes sont toutes les données qui sont acquises de l’extérieur de l’organisation. En marketing, elles sont souvent appelées données de seconde partie ou de tiers.
Cependant, les données externes arrivent sous de nombreuses formes et formes.
Nous devons faire trois distinctions essentielles entre les données externes traditionnelles, les données externes avancées et les données alternatives. Premièrement, la plupart d’entre nous sommes familiers avec les sources de données externes traditionnelles – dossiers gouvernementaux, services de statistiques, communiqués de presse, etc.
Alors que relativement peu d’entreprises l’ont largement utilisé, les données externes traditionnelles ont toujours trouvé leur place au sein de l’industrie financière et de plusieurs autres. Les données externes avancées visent cependant à attirer un public beaucoup plus large.
Des données externes avancées sont produites grâce à la surveillance Internet et à la collecte automatisée de données.
De nombreuses entreprises utilisent une certaine mesure de données externes avancées telles que l’analyse des sentiments des médias sociaux ou le suivi et la surveillance des avis des clients.
Enfin, les données alternatives ne sont pas tant un nouveau type de données ; c’est plutôt une qualité. Bien qu’il existe de nombreuses définitions de celle-ci, elle est généralement comprise comme le contraire des données traditionnelles. En d’autres termes, il s’agit de prendre des données qui n’ont pas été utilisées souvent et d’en tirer des informations exploitables.
L’imagerie satellitaire est un excellent exemple de données alternatives. Encore une fois, cela peut surprendre, mais il existe un cas d’utilisation assez direct pour le secteur financier de telles données.
Les chercheurs ont découvert que l’imagerie satellite des détaillants et d’autres acteurs importants du marché peut permettre aux investisseurs de déduire les fluctuations de valeur avant que tout le monde ne les rattrape.
Dans de tels cas, des données alternatives peuvent être utilisées pour prendre de meilleures décisions d’investissement.
Intégration de données externes avancées dans les pipelines existants
Les données externes nécessitent un certain dévouement, contrairement aux données internes, qui sont principalement collectées en tant que sous-produit d’autres processus métier. Il ne peut être acquis qu’en créant des équipes de collecte de données internes ou en les achetant auprès de fournisseurs tiers.
Cependant, avant même de commencer tout grattage Web ou toute collecte automatisée de données, trois choses doivent être décidées : quel type de données est requis, comment elles seront mises en œuvre et où elles seront stockées.
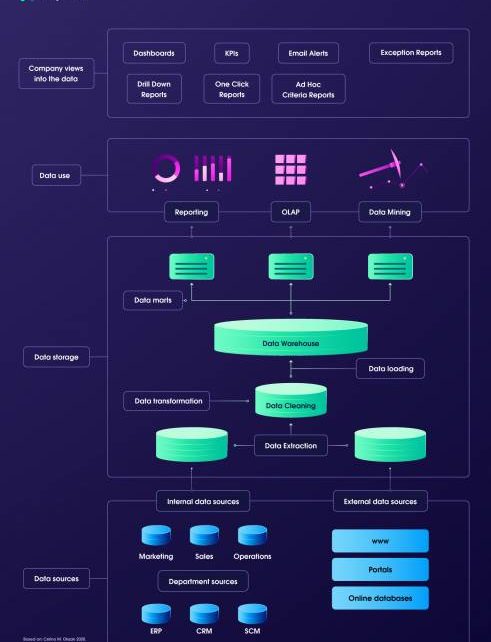
Comme je l’ai mentionné dans mon article précédent, les entrepôts de données devraient être l’endroit où toutes les données commerciales arrivent. Cependant, cela ne s’applique qu’aux données qui ne sont pas utilisées pour les opérations quotidiennes. Les données externes peuvent alimenter à la fois les opérations quotidiennes et être utilisées à des fins à plus long terme.
Si les données sont collectées pour des opérations quotidiennes, comme pour la tarification dynamique, les informations peuvent ne jamais se retrouver dans un entrepôt (ou se terminer différemment). Dans ces cas, le stockage à long terme sera probablement une réflexion après coup, car la tarification dynamique sera un réseau complexe d’API, de comparaisons mathématiques et de calculs.
Comment les données externes et alternatives avancées peuvent être comprises
D’autre part, certaines données externes et alternatives avancées ne peuvent être comprises que si elles sont stockées et analysées en relation avec des informations supplémentaires. Ces cas sont plus complexes et nécessitent une planification importante.
D’abord, toutes les données collectées doivent avoir un objectif particulier. Habituellement, ce but sera de soutenir ou de nier une hypothèse. Pour revenir à notre exemple d’imagerie satellitaire, ces données devraient être stockées à plus long terme et analysées manuellement. Il devrait être assigné un sujet et une attente spécifiques.
Seconde, il faut comprendre que des données alternatives pourraient ne pas s’avérer utiles dans certains cas. Par exemple, étant donné qu’il s’agit généralement de données supposées fournir des informations sur un phénomène particulier mais qui n’ont pas été testées de manière approfondie, des données alternatives peuvent s’avérer incapables de soutenir l’hypothèse proposée.
Finalement, les processus de collecte de données externes nécessitent plus de maintenance et de support que les processus traditionnels. Si l’entreprise ne dispose pas déjà d’un analyste ou d’une équipe d’extraction dédiés, il sera difficile d’utiliser des données externes ou alternatives avancées.
Construire des structures de soutien
Pour utiliser des données externes et alternatives avancées, des structures de support doivent être construites. Dans certains cas, ils peuvent être assez simples si les données sont acquises auprès d’un fournisseur tiers. Seules une équipe d’analystes de données et certaines pratiques de gouvernance seront nécessaires. Mais, bien sûr, la vérification de la qualité des données et d’autres processus seront toujours nécessaires.
Les choses se compliquent encore si aucun fournisseur de données ne peut fournir les informations nécessaires ou si une équipe de grattage interne doit être constituée pour d’autres raisons.
Étant donné que le développement technique approfondi est une chose sur laquelle je fais confiance à mes collègues, je vais sauter les détails essentiels. Au lieu de cela, trouver un fournisseur qui propose des solutions de grattage est le choix le plus simple pour la plupart des entreprises.
Néanmoins, une bonne intégration nécessitera une équipe dédiée aux données pour prendre en charge le flux, en particulier si les informations sont collectées à partir de plusieurs sources. Au moins trois étapes cruciales devront être franchies avant que les données puissent être déplacées vers un entrepôt : le nettoyage, la normalisation et l’assurance.
Les données extraites automatiquement de plusieurs sources ne seront pas unifiées, il y aura une corruption possible, ou elles peuvent simplement être inexactes.
Par conséquent, un nettoyage des données devra être effectué. Après cela, les données doivent être normalisées avant de pouvoir être déplacées n’importe où. Habituellement, il s’agit essentiellement de fixer des formats, des conventions de nommage et d’autres aspects structurels.
Enfin, l’assurance qualité est nécessaire avant de pouvoir être déplacée n’importe où, même si, contrairement à d’autres types de données, les données grattées auront souvent la qualité requise telle qu’elle a été décidée à l’avance. Dans les cas où certaines données sont acquises auprès d’un fournisseur, l’assurance qualité devient considérablement plus importante.
Conclusion
Une fois que les données externes sont impliquées dans le pipeline, les choses deviennent exponentiellement plus compliquées.
Les coûts augmentent également car la collecte automatisée de données nécessite soit une expertise technique, soit des capacités analytiques, soit les deux. En tant que tel, l’intégration de données externes dans les processus métier doit être soigneusement planifiée à l’avance.
Cependant, les bénéfices tirés des données externes sont énormes et ouvrent de toutes nouvelles opportunités de croissance.
Crédit d’image : George Morina ; Pexels ; Merci!
L’article Construire un (gros) pipeline de données de la bonne manière est apparu en premier sur zimo news.


